
这两年,AI 大模型写代码越来越强,是大家的共识。但有一个奇怪的现象:为什么模型越来越先进,写代码的 Token 费用反而越来越高了?
问题不在能不能写,而在靠不靠谱
我看到一个微博视频,两个人因为 AI 写代码这件事,发生了比较激烈的争执。
大概是一个人在做 AI 编程分享,台下另一个人认为,目前 AI 写出来的代码并不可靠,还是需要人工筛查。不然代码里一定会有各种潜在问题。如果不看就直接上线,是一种不负责任的行为。但台上做分享的人言辞激烈地反问,是不是现在不懂代码的人,就不配用 AI 写代码了呢?
原视频在这里:
https://weibo.com/tv/show/1034:5295965234725005
这里面的一些看法,和我最近的感受很像。
自从有了 AI 大模型以后,软件项目正在以越来越快的速度诞生。有不少项目明显是用 AI 写出来的,但给我的感觉是不稳定。文档经常找不到,遇到问题也不知道该去哪里解决。
例如 OpenClaw 这个项目就不算稳定,很多人吐槽它每次一升级,过去的配置就完全不能用了。这会让人觉得,这个东西不可靠,而且作者在开发时不够负责。
前段时间还有一个热门话题。Node.js 核心团队成员提交了一个改动 1.9 万行代码的巨大 PR。据说这个 PR 用了 AI,大大提高了开发效率,目的是给 Node.js 新增虚拟文件系统(VFS)。
这件事之所以引起巨大争议,是因为 Node.js 是软件世界非常核心的基础设施之一。这么大的 PR 会给 review 的人造成非常大的负担,也没有人敢轻易保证这些代码是可靠的。于是问题就来了,像这种重要的基础设施项目,到底能不能用 AI 写代码?如果能用,又应该怎么用?
我个人体感是,现在有些人用 AI 写代码的方式确实不负责任。他们不太关心代码到底写成什么样,有 bug 也不管,也不认真测试,反正直接发出来,然后鼓吹自己一天写了几千几万行代码,又做了多少个项目。
但项目质量并没有保证。
所以我觉得,至少在现阶段,对于比较严谨的项目,AI 写完代码以后,最起码要粗略看一遍,而不是相信它能全自动搞定。
我还有一个和视频里类似的疑问。对于那些完全没有技术基础的人,通过 Vibe Coding 的方式做项目,能做出可靠好用的产品吗? 会不会在后续的升级维护过程中,发现很多解决不了的问题?更严重的是,会不会存在一些问题,他们甚至没有发现?
例如我在小红书上看到过一个案例,不知道是搞笑段子还是真实情况。有人做了几个网页,然后发出来的网址是 localhost。localhost 只有他自己的电脑能访问,别人根本打不开。
对于不懂技术的人来说,他可能会觉得自己电脑上能访问,就等于别人也能访问。但实际上不是这样。

这些争议表面上看,是大家对 AI 写代码这件事态度不同。
但往深一点看,真正的分歧其实不是 AI 能不能写代码,而是它写出来的东西到底能不能被信任。对个人玩具项目来说,能跑起来也许就够了。但对基础设施、团队协作、长期维护的项目来说,能跑只是起点,可靠才是重点。
为什么 AI 不能简单类比成编译器
在群里和别人讨论时,也有人提出了不同看法。
编译器刚诞生时,肯定也有人有过类似担忧。但到今天,已经没有人写代码还要去看编译器生成的汇编是什么样了。所以他们相信,AI 最后也会进化到这种程度。
但我觉得,AI 和编译器在原理上有一个根本差别。
AI 大模型本质上是一个按概率生成 Token 的系统,并不是一个很稳定的系统。即使你给同一个模型完全相同的上下文和提示词,多调用几次,它每次输出的结果也不太一样。
编译器的本质,是把一种形式化输入转换成另一种形式化输出。只要输入一样、环境一样,输出通常就是确定的。
但大模型不是这样。它不是在严格执行一套形式规则,而是在根据上下文做概率预测。编译器追求的是确定性,而大模型擅长的是近似性。 这两者在体验上可以越来越像,但底层并不是一回事。
那问题就来了。使用这么不稳定的东西,怎样才能让它稳定输出可靠的代码?再过几个月,或者几年后,AI 真的能像编译器一样,稳定可靠地写出代码,而完全不需要人工 Review 吗?
负反馈如何让不稳定系统变可靠
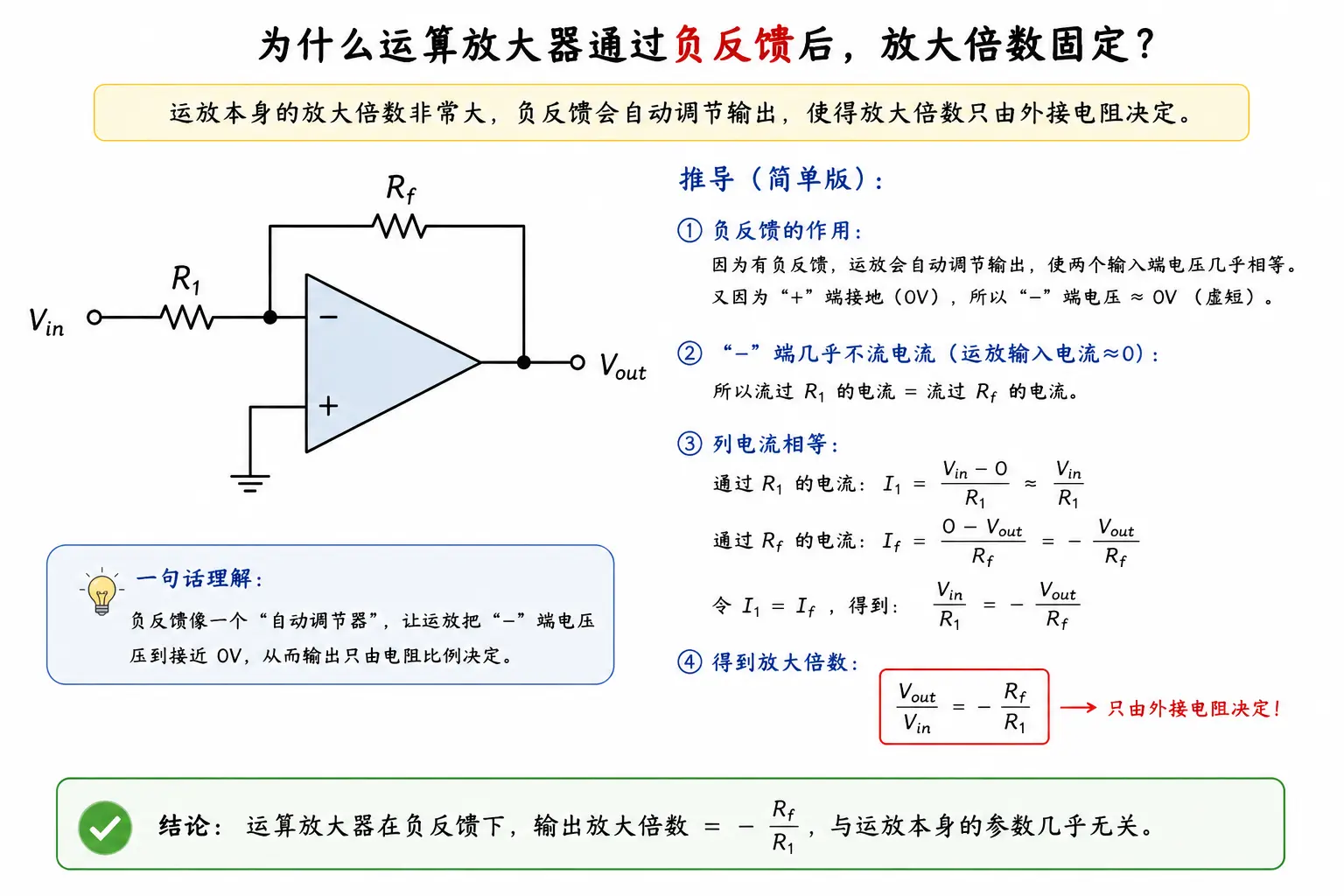
想到这里,我突然想起大学模拟电路课上学过的运算放大器。
当我们对着话筒说话,它会产生一个很微弱的电信号。但是想把这个电信号用喇叭或者庞大的音响播出来,就需要一个很强大的电信号去驱动,这就不得不使用放大器。
放大器的基本组件一般是三极管。三极管可以把电路信号放大,但它本身的稳定性很差。它有热效应,只要持续工作,温度升高,放大倍率就会变化。而且还会受到电流等各种干扰,导致放大率持续波动。这样一来,原始信号就可能失真。
那工程上是怎么解决这个问题的?
答案就是负反馈。
我们先把多个三极管串联起来,做成一个具有极高放大倍率的运算放大器,一般至少有几万倍。通常把这个放大倍数称为开环增益。
再通过电阻,把部分输出反馈回输入的负极,形成负反馈。这样一来,电路的整体放大倍率可能只剩下 10 倍,这个放大倍数叫闭环增益。
看起来是浪费了大量性能,但换来的结果是,它可以长期稳定地保持在 10 倍。运放电路的放大倍数取决于电阻阻值,和运放本身的倍率(开环增益)几乎没有关系。即使有热效应和电流干扰,也不影响最终结果。
也就是说,我们牺牲了很多性能,换来了系统强大的稳定性。
负反馈在工程里很常见,在很多领域都有实际应用。例如 PID 算法里也会用负反馈来实现系统稳定。无人机之所以能稳定悬停、稳定控制姿态,离不开 PID 算法。
我觉得这和今天的 AI 很像。模型本身的能力越来越强,就像开环增益越来越高。但如果没有反馈约束,它的输出能力越强,出错时的破坏力也越大。真正让系统能用的,往往不是一味把能力做大,而是想办法把它放进一个稳定的闭环里。
从这个角度看,所谓让 AI 更可靠,其实不是让它永远不犯错,而是让它即使犯错,也能更快被发现、更快被纠正、更少把错误带到最终结果里。
为什么 AI 写代码越来越贵
再联想到大模型写代码的发展过程,我觉得这条路已经很像了。
聊天阶段
我记得两年前刚开始用 ChatGPT 写代码时,最让我震惊的是,它居然能写出像那么回事的代码片段。复制粘贴过去,还真能跑起来。
但那时候也经常会遇到语法错误,甚至代码根本编译不过。很符合直觉,毕竟 Token 是按概率生成的。既然是概率输出,就完全可能出现一些不符合语法格式的结果。
产品形态上,当时 ChatGPT 就是一个聊天软件,只能处理一些比较短的代码片段,代码的复制粘贴也都要人工进行。
价格方面,那时 ChatGPT 聊天基本还是免费的,也很快就能返回结果。
Agent初步阶段
到了去年的 7 月份,我已经开始用 Cursor 写代码了。那时候已经发展到 Agent 模式,也就是大模型可以自己读写文件,自己做多步分析,最后把代码输出出来。这里面的每一步,其实都需要多次大模型调用。
而我用 Cursor 的时候,它基本已经不太会出现语法错误了。原因是它写完代码以后会主动运行语法检查,还可以写测试、跑测试,发现问题再回去修改。
产品形态上,Cursor 算是当时最先进的工具之一。它基于 VS Code 这种常规代码编辑器,一方面可以在编辑界面按 Tab 键帮你补全代码,另一方面,会在右边增加一个聊天窗口直接和 AI 交互,并且在聊天结束后可以查看到底改了什么。主界面还是代码编辑器,AI 则是辅助。
使用成本上,你给 AI 发一句话,它把任务做完,整个过程可能要几分钟,一天可能会消耗几百万 Token。那时候我也已经开始为 Cursor 付费了。
Agent优先,持续运行
到了今年,又开始出现 Harness 编程、Spec Driven 之类的思路。
现在的流程通常是这样。每次大模型输出一些内容,Agent 会先做一些处理和思考,然后才写入文件。加上一些技能和流程约束后,还可以要求它先给代码写测试,再去实现。写入文件以后,它会跑测试和各种工具检查。如果发现有问题,就会反复修改,直到问题解决。最后到我这里,我再给它人工反馈,它再改,直到得到我想要的结果。
产品形态上,到了现在这个阶段,所有主流写代码的 Agent 工具,都已经发展到了以 Agent 聊天为主的界面。你可以和 AI 展开很多个对话,界面的主体就是对话窗,而具体的代码改动只是一个侧边栏,简单看一下就行了。
使用成本上,一条看起来不复杂的指令,AI可能要跑挺久的,我们追求让Agent独立运行几个小时甚至几天。我算是比较重度的用户了,现在写代码一天可能要花 1 亿到 2 亿 Token。为大模型持续付费,现在也已经是很普遍的事情,不少程序员每个月都要花几百甚至几千块。
发展趋势
这里就有一个很有意思的问题。
如果回头看这两年的工具演化,会发现一个很明显的趋势:AI 并不是在变成一个更便宜的代码生成器,而是在变成一个更昂贵的验证系统。
尽管大模型的准确率越来越高,显卡性能也越来越强,但我们用大模型写代码花掉的 Token 和总支出,反而越来越多。
我的理解是,这本质上也像一种负反馈机制。
本来大模型可以直接把代码吐出来,但现在我们要对它做测试,要让它跑 Harness 闭环,要让它自己完成验证,还要人工核验。甚至有些人会做多 Agent,让专门的 Agent 去审查代码、提出反馈。
这当然会让输出代码的成本大幅提高,但也换来了可靠性的增加。
也就是说,真正贵的,不是生成代码这一步,而是为了让这段代码变得可交付、可维护、可上线,我们在外围叠加的那整套确认机制。代码可以很便宜地生成出来,但可靠性从来都不便宜。
如果继续沿着这个思路走下去,也许在不远的将来,我们真的可以让 AI 持续稳定地输出非常可靠的代码,并且连现在的各种 Skill 配置都不需要了。
到那个时候,人彻底不需要再看具体代码了,只需要看文档和结果是否符合预期就够了。
但代价也很明显,Token 的消耗量大概率会比现在高很多,甚至可能成倍增加。到那时,能不能获取便宜的 Token,会成为一个非常重要的事情。
更像人类,也更昂贵
我还和人讨论过另一个问题。
现在的大模型普遍已经能理解图片里的大致内容。如果让它做一个前端界面,它也可以通过截图去理解界面里有什么元素,哪些元素实现有问题,哪些 UI 交互可能有问题。
但它背后的原理,要么是隔一段时间截一张图,分析这张图,再尝试操作一下;要么结合 Accessibility 接口分析界面元素。如果是网页,也可以直接调用各个 DOM 元素的接口。现在很多 Agent 的 Computer Use 模式,大体上也是类似的思路。
我观察过豆包 App 里的视频通话功能,它也是隔一段时间截一张图来分析。所以有时会发现,你问它一个问题,它回答的还是几秒之前的画面内容。
以目前的技术水平,AI 在软件开发,特别是前端开发方面,只能完成一部分工作。当然这也足以大大提高生产效率。但如果想让它达到接近人类的水平,还有很长的路要走。
第一个问题是,AI 现在对图片的理解还没有那么好。
有个前端开发朋友跟我聊过他现在面临的问题。设计师给了他一张图,里面不是常规的卡片式界面布局,而是一个促销 Banner,包含一些图片元素和折扣文字。
但 AI 做出来的效果明显有偏差。它实现的文字元素,尺寸和位置可能没能准确和背景图片对齐,所以看起来会有明显 Bug,或者就是很丑。但 AI 自己并没有很好的审美,它并不知道这些文字到底该和背景图里的哪些元素精确对齐。
另一个问题是,对连续动态画面的理解。
如果界面是静态的,AI 或许还能通过截图分析出哪些元素不对,再把它摆正。但如果界面需要更细致的动效,特别是游戏画面,难度就会瞬间上来。AI 不能靠隔很长时间截一张图的方式去理解,而是要持续截图,判断动效是否连贯。
它最终要处理的就不是单张图片,而是一个视频流。并且在视频理解的同时,它还要操作界面,才能知道这个功能是否流畅。
先不说算力,光是把视频流实时传到远程大模型服务器上,按现在很多人的家用网络速度,就可能出现明显的延迟和卡顿。很多人用 VNC 远程操作 Linux 电脑时,就已经会因为网络速度限制而觉得不流畅。
再说算力,这种情况需要的算力很可能是爆炸式增长的。它需要消耗的性能和 Token,可能会大到难以想象。仅靠现在这条技术路线慢慢往前走,大概还得很久。也许要等模拟计算机、量子计算机之类更底层的技术突破,才能做到。
现实世界更需要高密度反馈
这类问题不只出现在软件开发里。无人驾驶、机器人、实时视频理解,本质上都要求模型持续接收环境反馈,再持续修正自己的判断。
这些场景都要求 AI 持续分析当前画面,并实时做出判断,所以同样会面临类似的问题。很多现有方案实际上会依赖离线模型,因为数据量实在太大。如果完全靠在线模型,网络速度和延迟往往跟不上。
即使是复杂的在线模型,对图片的分析和理解也还有不少问题。而离线模型受限于本地算力和模型规模,很多任务只会更难。特别是机器人场景,想让它做一些精细化操作,那就太困难了。
一旦任务从生成一次答案,变成持续盯住现实世界并不断纠偏,成本就会急剧上升。所以从这个角度看,AI 想真正替代很多人类工作,难点未必只是模型够不够聪明,而是我们能不能承担这么高密度的反馈成本。
所以总结来说,AI 想要深入到更多真实场景里,进一步提升人类的工作效率,还是任重而道远。
如果觉得文章有帮助,欢迎分享转发,也欢迎关注我的公众号“搬砖的小明”,及时获取更新
