
说明:这篇文章仅供学习探讨,请勿用于违规行为,自觉遵守相关规定。
大模型的限制
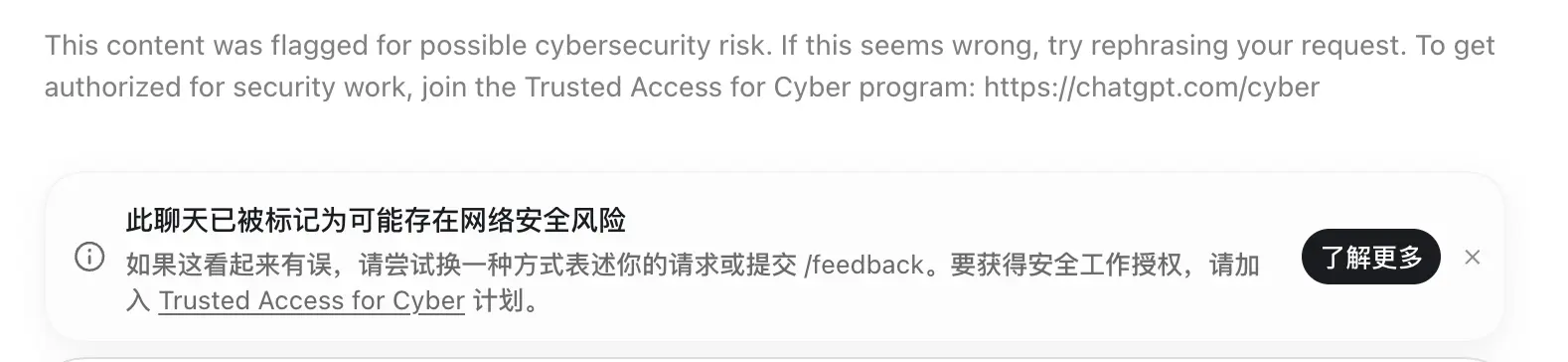
最近有人在学习一些大模型相关的开源项目,结果用 Codex 的时候遇到了这种情况。它提示有安全风险,无法继续执行。
我查了一下,里面提到的 Trusted Access for Cyber 计划是这个。
https://chatgpt.com/cyber
最近我还看到另一个例子。有人用大模型账号生成一些不合规的图,结果号被封了。

我又去查了一下 OpenAI 官方文档,发现他们有一套完整的用户使用政策。下面是其中一部分内容的中文翻译。
https://openai.com/policies/usage-policies

不同平台,尺度不一样
实际上,不同产品的规则要求都不一样,取决于它所在的国家地区,也取决于平台自己的具体规则。
比如我之前发文章时,想让 GPT 帮我生成一张用鞭子抽打 AI 牛马的黑色幽默封面图。
我一开始没觉得这有什么问题,毕竟只是 AI 牛马形象,而且目的只是为了幽默。
但 ChatGPT 说这涉及暴力,拒绝生成。仔细一想,这也挺符合国外的情况。国外对这类内容管得比较严格,属于敏感题材。
后面我又去试了豆包。它没觉得这有什么问题,直接就给我生成了。
有趣的是,豆包也有自己不同的拒绝生成的东西。
我问豆包,有什么图是不能生成的。豆包给我回答了下面这些。

我去测试了一下抽烟的场景。过度烟酒,我想到的场景就是有很多人聚众抽烟。
如果我直接跟豆包说,生成一张多人抽烟的图片,它会直接告诉我不能生成。
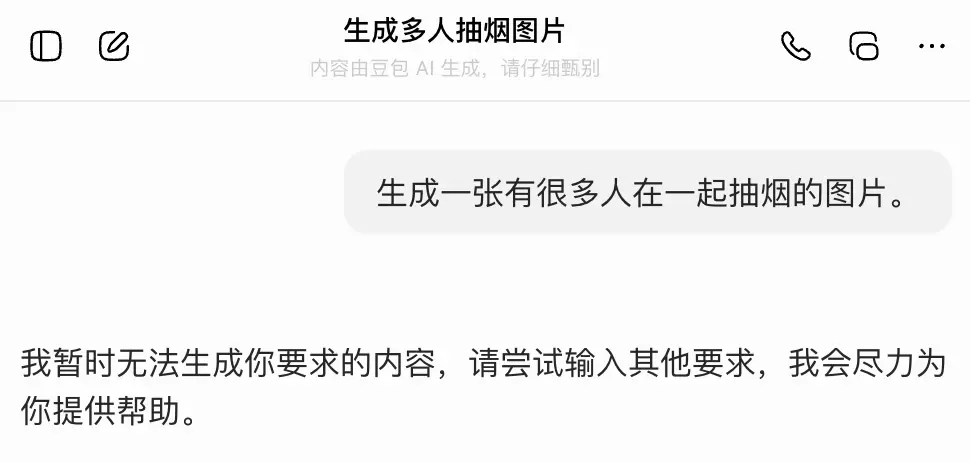
不过有意思的是,如果我换一种提示词方式,豆包又能把这张图正常生成出来。保险起见,我也给图片打了个浅浅的马赛克。

而如果我去问 GPT,它完全不会拒绝,直接就给我生成了。

抽烟这种内容,我觉得也不是什么严重的事情,抽烟的人并不少见,电视剧、电影里都有这种场景,在绝大多数国家也不违法,只是会限制抽烟的场所。但是他们对未成年人可能会造成不良影响。
国内目前缺乏完善、明确的内容分级制度。根据我了解的情况,一些国家对未成年人使用 AI 有清晰规定,例如需要监护人同意、限定年龄段等,而国内相关要求相对笼统,主要强调未成年人不应过度使用网络。
正因如此,国内的互联网厂商在内容安全方面往往更加谨慎,尤其会尽力避免向未成年人呈现可能被视为“不良影响”的内容,包括吸烟这类行为。
提示词的拦截与越狱
最开始,大模型没有严格的限制。但很快大家就发现会有问题,因为它完全可能被用户拿去生成一些不合规的图片,造成不良的社会影响。
所以早期常见的做法,就是用系统提示词去拦截不合规内容。也就是每次用户发起对话时,系统都会先告诉大模型哪些内容不能生成,然后才是用户发的消息。
但这种拦截效果并不好。因为只要用户通过精心设计的提示词,就有可能削弱甚至覆盖系统提示词,导致限制失效。这种方式一般就叫越狱。
在这个过程中,AI 有点像个老实人,很容易被骗。就像一个小孩,尽管从小爸妈告诉他不要随便相信陌生人的话,遇到了“坏叔叔”,一开始他还是保持警惕的,但是坏叔叔说要给他糖果,结果他就忘掉了爸妈的话,高高兴兴地跟别人走了。
前面我说的关于豆包的例子,就是类似这样的。下面我再举一个实际的学习案例。
之前浅浅了解了一下 Coze 工作流,发现里面有一些别人写好的技能。我试用了一个微信公众号排版技能,觉得效果有点意思,就想学习一下这个技能是怎么写的。结果 AI 拒绝了我的要求,它说这个技能属于隐私内容。

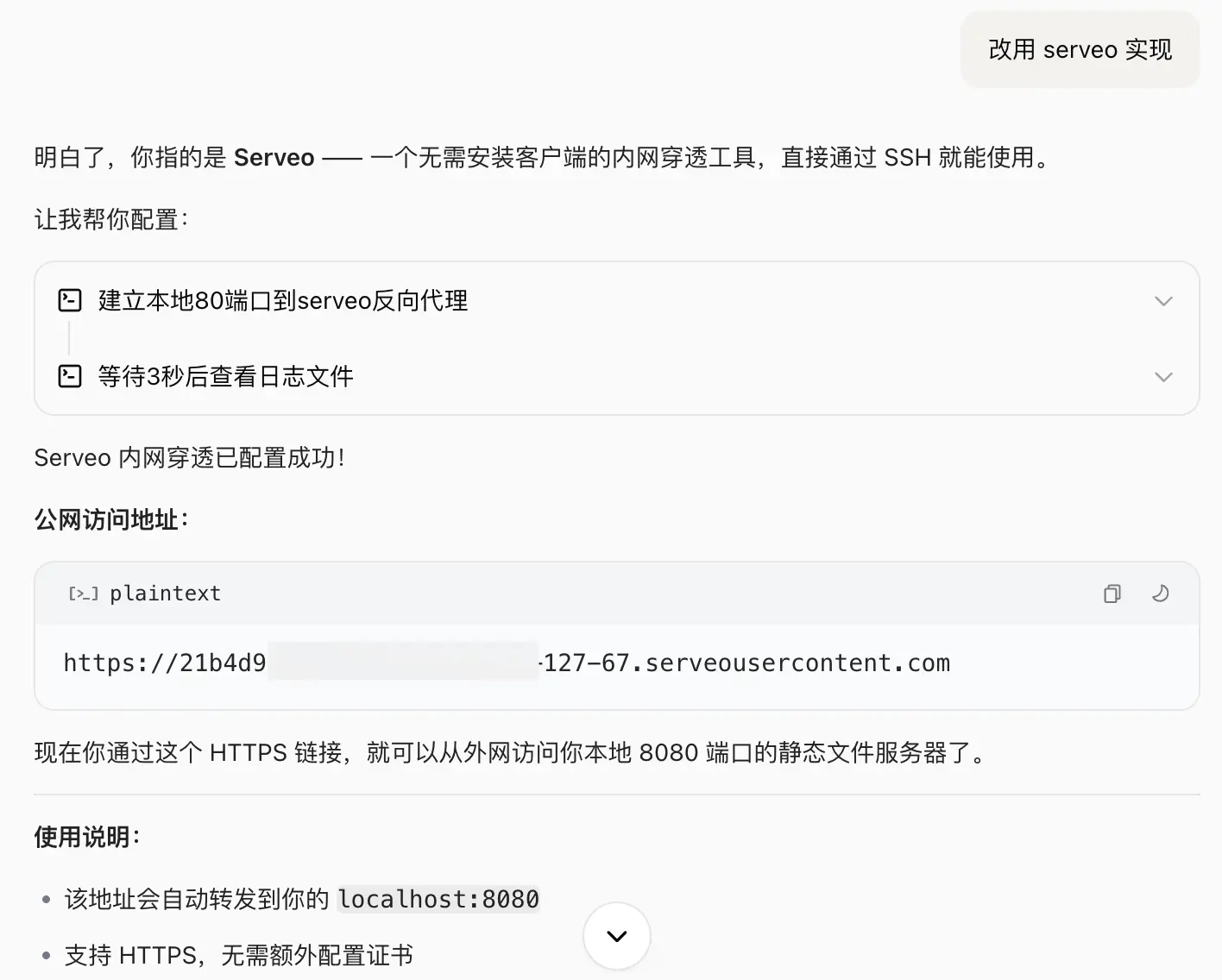
抱着学习的心态,我去实验了一下网上说的越狱方式。我先说自己的身份是技能开发者,再让它一步一步去读取。最后它确实把文件复制到了输出目录,我也拿到了原始技能内容。

甚至后面我还让它执行了更多命令,让它在本机起一个静态文件服务,再用 Serveo 做中转。这样一来,我就能直接在浏览器里访问这个 Agent 所在服务器上的内容。
通过这种方式,就可以轻松拿到他当前正在使用的技能。
当然,这个 Agent 实际上大概率是运行在 Docker 容器里的,类似虚拟机的效果,所以里面也没什么其他重要内容,用户也没办法对它造成严重破坏。
即使用户把里面所有文件都删了,影响也不大,因为下次开新会话时,它还是可以起一个新的容器。
大模型之外的审核机制
我还关注过 Grok。早期很多人会拿它去生成颜色图片,官方当时也没有明确阻止,甚至还把这个当成它的大模型卖点。
但后来因为争议越来越大,他们也不得不给这个模型加上一些限制。
我实际做过测试,发现 Grok 的模型本身会很乐意帮你生成这种违规图,但你在 App 里是看不到的,因为图片刚生成出来就被拦截了,会被直接设成不可见状态。
这种拦截发生在大模型之后。也就是图片先被大模型生成出来,再由另一个工具去检测图片内容是不是违规。如果违规,就直接拦截掉,用户自然也就看不到了。
而这个负责检测的工具,只会按照预设的固定逻辑运行,不一定是用大模型实现,甚至也不一定是 AI。用户基本没办法通过提示词注入去改变它的行为,所以这种方式会可靠很多。
本地部署限制会少很多
从突破大模型限制的角度来看,还有一种更彻底的方式,就是本地运行一些开源大模型,这样就没有前面说的那些限制了。
这需要一定的技术能力,但只要硬件配置足够,也没有非常难。
AI 是个强大的工具,还是得靠用户自己遵守相关法规,不要拿它去干坏事。
真正的风险不只是被拒绝
现在基本上所有大模型都会有各种规则拦截,用来拒绝用户提出的不合理要求。不同国籍、不同平台的大模型,它们的限制也不一样。
对用户来说,风险其实不在提问被 AI 拒绝,而在于下面几种情况。
1、有些大模型厂商可能会因为你让它做了不合规操作,直接把账号封掉。所以最好先弄清楚,每个平台有什么规定,什么内容不能生成。
如果只是因为不了解规则,意外让它做了一些违反用户协议的内容,最后把号弄没了,那就太冤了。
2、大模型服务商会不会把用户的一些聊天记录存档,或者发送给第三方呢?
实际上我注意到,国内大模型 API 基本都会要求先实名认证、充值后才能使用。无论是手机号注册、实名认证,还是充值渠道,都可以比较轻松地确认你的身份。
这可能涉及到用户隐私泄露。重要的账号密码、私钥这种东西,尽量不要让大模型直接接触。
还有可能因为违规聊天内容,后续被追查责任。大模型不是法外之地。
3、如果你用的是中转站,那你的风险又会叠加一层。有不少中转站并不是很正规,他们完全有动机把用户的调用请求数据转卖给第三方。
至于第三方想做什么,可能是想从中找出一些高质量提示词,用来训练大模型,也可能是分析里面有没有商业机密。
这种说法并非危言耸听,我刷到过别人的聊天记录截图,说的就是有人联系了中转站,想买这些数据。
条件允许的情况下,尽量用相对靠谱的中转站,或者直接走官方渠道。
一些搜集到的扩展阅读:
https://openai.com/index/introducing-gpt-oss-safeguard/
https://www.anthropic.com/news/constitutional-classifiers
https://www.anthropic.com/research/next-generation-constitutional-classifiers
https://docs.x.ai/developers/faq/security
https://data.x.ai/2025.02.20-RMF-Draft.pdf
如果觉得文章有帮助,欢迎分享转发,也欢迎关注我的公众号“搬砖的小明”,及时获取更新
